Exploring Windows Server 2025: What's New and What's Changed - Part 1
·689 words·4 mins
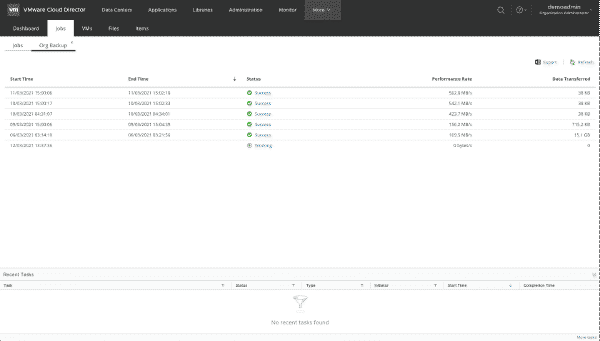
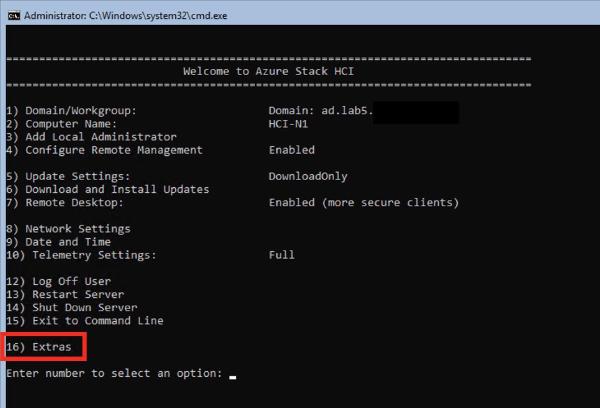
Windows Server 2025 is coming! In Part 1, we explore the new installer UI, compare Windows Features (hello NetworkATC!), note removed features like PNRP and SMTP, and review PowerShell module changes.