
So you’ve set up an Azure Stack HCI Cluster and everything’s running great, but there is this nagging feeling in the back of your mind. It’s a hybrid setup, with some type of flash cache sitting in front of spinning disk, and you start to wonder how hard you’re pushing that cache, and how long it will last.
Thankfully with Windows Server 2019, there are many in-built tools and commands to help work out just that!
In this post, we are going to look at:
- Where’s my cache?
- Storage History commands
- Looking back with Cluster Performance History
- Pulling it all together into a new tool
- So what’s next?
Where’s my cache?#
Storage Spaces Direct, the technology responsible for that super-fast storage in your Azure Stack HCI deployment, does a great job of hiding away all the boring details and steps when you build a cluster. It simplifies the whole process down to two commands, New-Cluster and Enable-ClusterS2D.
But don’t worry, identifying your cache drives is still just as simple once things are up and running. They’re identifiable from the usage property of a physical disk, and you can find them with a simple command
Get-PhysicalDisk -Usage JournalThis will return a nice table of all those cache drives (see below). So now we have our cache drives, let’s look at what they’ve been up to.
DeviceId FriendlyName SerialNumber MediaType CanPool OperationalStatus HealthStatus Usage Size
-------- ------------ ------------ --------- ------- ----------------- ------------ ----- ----
2001 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SSD False OK Healthy Journal 745.21 GB
1003 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SSD False OK Healthy Journal 745.21 GB
1002 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SSD False OK Healthy Journal 745.21 GB
2003 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SSD False OK Healthy Journal 745.21 GB
2002 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SSD False OK Healthy Journal 745.21 GB
1000 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SSD False OK Healthy Journal 745.21 GB
1001 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SSD False OK Healthy Journal 745.21 GB
2000 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SSD False OK Healthy Journal 745.21 GBStorage History commands#
One of the many commands added in Windows Server 2019 to make our lives easier is Get-StorageHistory
This command will go retrieve several stored stats, some from the SMART data on the disks, and others maintained by the OS.
Retrieving data about a disk is as easy as passing it through to the command!
PS > Get-PhysicalDisk -Usage Journal | Get-StorageHistory
DeviceNumber FriendlyName SerialNumber BusType MediaType TotalIoCount FailedIoCount AvgIoLatency(us) MaxIoLatency(us) EventCount 256us 1ms 4ms 16ms 64ms 128ms 256ms 2s 6s 10s
------------ ------------ ------------ ------- --------- ------------ ------------- ---------------- ---------------- ---------- ----- --- --- ---- ---- ----- ----- -- -- ---
2001 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SAS SSD 645,141,521 84 598.9 513,106.8 246 61 3 110 34 27 1 10
1003 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SAS SSD 1,317,886,434 73 1,375.2 515,510.1 244 62 1 104 37 16 24
1002 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SAS SSD 1,326,895,280 76 1,522.3 517,003.1 244 62 2 100 40 18 22
2003 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SAS SSD 969,169,213 136 710.7 513,710.2 246 61 4 96 45 22 2 16
2002 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SAS SSD 1,144,926,978 177 1,872.4 514,277.1 246 62 3 95 45 29 1 11
1000 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SAS SSD 1,171,742,589 71 1,190.9 517,184.0 244 61 3 104 36 20 20
1001 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SAS SSD 1,112,541,260 65 1,149.3 514,377.9 244 62 2 113 27 19 21
2000 ATA INTEL SSDSC2BA80 BTHV00000000000OGN SAS SSD 1,079,017,077 157 980.1 513,973.3 246 60 4 92 50 22 1 17As you can see, the default output of the command has a heavy interest in the latency of the disk, but nothing about how many writes are going to our disks, or what timeframe this is over.
Focusing in on a single disk, and using Format-List we get more of a picture about the details hidden away about our disk.
PS > Get-PhysicalDisk -Usage Journal | Select-Object -First 1 | `
>> Get-StorageHistory | Format-List *
Version : 10
FriendlyName : ATA INTEL SSDSC2BA80
SerialNumber : BTHV00000000000OGN
DeviceId : {268d880b-33a3-6c8c-bc95-f8361285c068}
DeviceNumber : 2001
BusType : SAS
MediaType : SSD
StartTime : 2/14/2020 3:18:55 PM
EndTime : 2/25/2020 4:03:54 PM
EventCount : 246
MaxQueueCount : 36
MaxOutstandingCount : 32
TotalIoCount : 645141521
SuccessIoCount : 645141437
FailedIoCount : 84
TotalReadBytes : 10794587081216
TotalWriteBytes : 8966117642240
TotalIoLatency : 3864066151996
AvgIoLatency : 5989
MaxIoLatency : 5131068
MaxFlushLatency : 1378
MaxUnmapLatency : 0
BucketCount : 12
BucketIoLatency : {2560, 10000, 40000, 160000...}
BucketSuccessIoCount : {293181558, 238929981, 109484596, 3536792...}
BucketFailedIoCount : {84, 0, 0, 0...}
BucketTotalIoCount : {293181642, 238929981, 109484596, 3536792...}
BucketTotalIoTime : {346273222942, 1227862537245, 2109283312866, 176980948128...}
BucketIoPercent : {45, 37, 17, 1...}
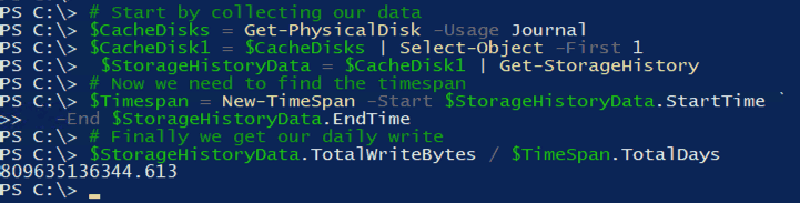
BucketHighestLatencyCount : {61, 3, 110, 34...}Hey there we go, those look more interesting. Now we have both a timeframe to work with and a bytes written counter for the disk. From here we can use some simple maths to determine the average amount of data being written every day.
$$Daily Write = \frac{TotalWriteBytes}{(EndTime - StartTime)}$$
In Powershell, this is what it would look like
| |
Looking back with Cluster Performance History#
Another great feature introduced in Windows Server 2019 is the Cluster Performance History, and I could write a whole post just on this. At a high level, it gathers performance counters for a huge number of components in a Storage Spaces Direct cluster and saves them to a database over time, allowing for easy querying via Powershell.
This is great in our case, as we can drill into the performance data of our cache drives over time without having to worry about having the right monitoring setup in the first place.
Just as with the Get-StorageHistory command, the Get-ClusterPerf command can be fed physical disks through the pipeline to find their related data.
PS > Get-PhysicalDisk -Usage Journal | Select -First 1 | Get-ClusterPerf
Object Description: PhysicalDisk BTHV00000000000OGN
Series Time Value Unit
------ ---- ----- ----
PhysicalDisk.Cache.Size.Dirty 02/26/2020 18:17:56 24.45 GB
PhysicalDisk.Cache.Size.Total 02/26/2020 18:17:56 709.01 GB
PhysicalDisk.IOPS.Read 02/26/2020 18:18:00 4 /s
PhysicalDisk.IOPS.Total 02/26/2020 18:18:00 116 /s
PhysicalDisk.IOPS.Write 02/26/2020 18:18:00 112 /s
PhysicalDisk.Latency.Average 02/26/2020 18:18:00 99.88 us
PhysicalDisk.Latency.Read 02/26/2020 18:18:00 1.06 ms
PhysicalDisk.Latency.Write 02/26/2020 18:18:00 63.13 us
PhysicalDisk.Throughput.Read 02/26/2020 18:18:00 599.18 KB/S
PhysicalDisk.Throughput.Total 02/26/2020 18:18:00 1.19 MB/S
PhysicalDisk.Throughput.Write 02/26/2020 18:18:00 615.18 KB/SThe obvious performance counter here is PhysicalDisk.Throughput.Write. While this tells us the write throughput of our cache drives, the more interesting stat here is PhysicalDisk.Cache.Size.Dirty. This counter shows how much data is currently in the write cache portion of the disk, over time it will shrink if no new writes come in and the data is flushed through to the capacity disk behind the cache.
By default, the Get-ClusterPerf command will only return the most recent data point, giving a limited snapshot of what is going on. Using the -Timeframe parameter we can access data for the last hour, day, week, month or even year!
Using a longer period, we can feed the data into Measure-Object to find the average over time.
Pulling it all together into a new tool#
While accessing all this data has been pretty easy so far, if you want to start looking at it across multiple drives, and multiple servers in a cluster, then currently that’s a lot of manual work.
And so I wrote Get-S2DCacheChurn.ps1, a script that allows you to query a cluster and return this data from all cache disks in all cluster nodes.
Using the commands we’ve already looked at, we can use the size of the cache drives, and the average daily write we calculated, to estimate the Drive Writes per Day (DWPD) stat.
So putting it all together, the output looks a little like this
Cluster ComputerName Disk Size EstDwpd AvgDailyWrite AvgWriteThroughput AvgCacheUsage
------- ------------ ---- ---- ------- ------------- ------------------ -------------
Cluster1 Node1 Slot 0 745.21 GB 1.6x 1.18 TB 19.71 MB/s 3.35 GB
Cluster1 Node1 Slot 1 745.21 GB 1.0x 756.15 GB 12.30 MB/s 21.51 GB
Cluster1 Node1 Slot 2 745.21 GB 1.8x 1.28 TB 21.25 MB/s 4.45 GB
Cluster1 Node1 Slot 3 745.21 GB 1.4x 1.02 TB 16.92 MB/s 2.44 GB
Cluster1 Node2 Slot 0 745.21 GB 1.3x 1,000.90 GB 16.17 MB/s 2.23 GB
Cluster1 Node2 Slot 1 745.21 GB 1.3x 932.73 GB 15.08 MB/s 2.05 GB
Cluster1 Node2 Slot 2 745.21 GB 1.5x 1.11 TB 18.45 MB/s 2.86 GB
Cluster1 Node2 Slot 3 745.21 GB 1.5x 1.09 TB 18.07 MB/s 2.49 GBNow we can compare these stats to the specs sheets provided by the drive manufacturers to see if everything is healthy, or if the drives are going to burn through their expected lifetime of writes before you’re ready to decommission your cluster.
This might seem like something you don’t need to worry about, because you’ve got warranty after all, but if all of your cache drives have been running for the same amount of time, with similar write usage, then it won’t go well for your cluster if they all fail around the same time.
As always, the script is up in my Github repo, and you can find it here
Or if you want to download it and try it out, simply run the below command
| |
The script has the following parameters:
- Cluster
- This can be a single Azure Stack HCI Cluster or multiple Clusters
- LastDay
- Returns data for only the last 24 hours
- Anonymize
- Removes identifiable information from the results, so that they can be shared.
So what’s next?#
Going back to that shiny new Azure Stack HCI Deployment you put in, and how well it’s running, remember the job isn’t done. Check-in on it, use the tools available to monitor show it’s going overtime.
Have a link about using tools like Azure Monitor, Grafana, InfluxDB, and other modern tools to not just extract this data Adhoc, but continuously. Allowing you to monitor any degradation over time and also alert on major issues.
Any come on over to the Azure Stack HCI Slack Community, chat to others running clusters like you, hear about what works well for them and issues encountered.
And as always, let me know if you have any further questions, on here, Twitter, or Slack.