UPDATE(2017-09-19): Microsoft have officially recognized the bug and have a KB describing the symptoms and workaround much like the below. See here: https://support.microsoft.com/en-us/help/4043361/disks-in-maintenance-mode-status-after-september-cumulative-update-kb
I was patching our dev cluster the other day and came across a new issue when applying the latest September Cumulative Update (KB4038782), and it seems others on the internet have hit this issue as well.
Background#
First, a bit of background on the expected behaviour when performing maintenance:
Basically when you are performing maintenance on a Storage Spaces Direct (S2D) Cluster, you would normally use Failover Cluster Manager (GUI or Powershell) to Pause and Drain the node first, and then patch and reboot it, and eventually resume and fail back its rolls.
Now doing this would in turn, mark the physical disks associated with that host as being in maintenance mode during this period to redirect IO away from them, and then when the host is resumed, the disks are taken out of maintenance mode and IO is resumed to them and the storage re-sync begins.
This is all automated for you if you use the awesome Cluster Aware Updating (CAU) features, which will patch whole clusters for you without your manual involvement.
Problem#
What I found while patching this month, both manually and with CAU, is that when the hosts go into maintenance mode and are paused and drained, their disks are also marked as being in maintenance mode, however after patching and rebooting, they get resumed but their disks stay in maintenance mode.
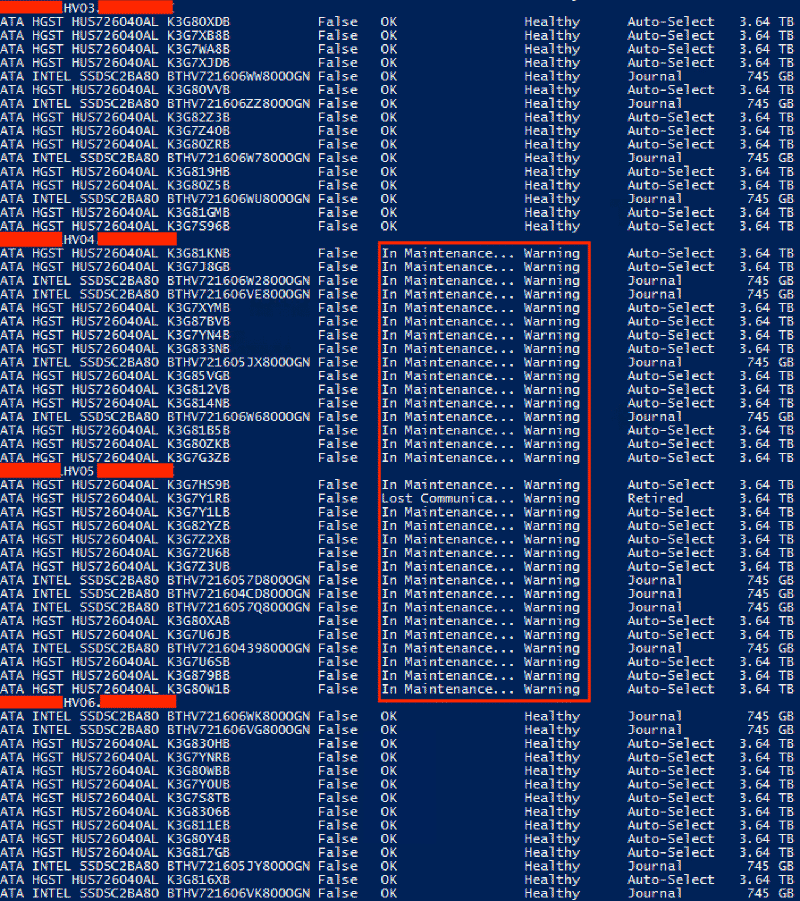
What this means, is that if you’re using CAU, it will fail to patch the cluster after the first host or two, depending on your resiliency, as it doesn’t have enough spare capacity left to take more disks out of maintenance mode, even though all the hosts are up and healthy.
You can check this by running the following Powershell on a cluster host
Get-StorageNode | %{ $_.Name; $_ | Get-PhysicalDisk -PhysicallyConnected }Workaround and Fix#
Now, if you’ve already started patching and need to recover from this, you can use the following Powershell to remediate the hosts you’ve patched
Repair-ClusterStorageSpacesDirect -Node [hostname] -DisableStorageMaintenanceMode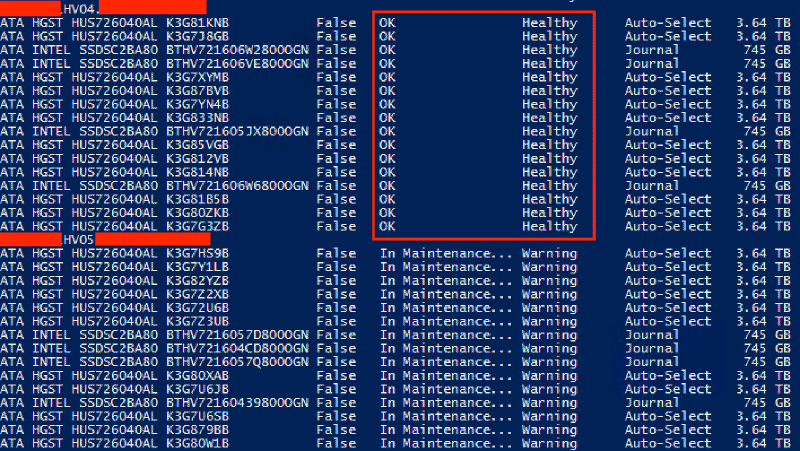
If you haven’t patched, then you can avoid this by choosing to ‘Pause and Don’t Drain’ your hosts in Failover Cluster Manager, and then manually live migrate your VMs and Virtual Disks to other cluster members before patching and rebooting the host, as this will avoid the physical disks being put into maintenance mode in the first place.
My take on the problem#
Having dealt with S2D for a while, I think what we’re seeing here is a change in behaviour to how maintenance is performed on S2D Cluster hosts, and so when this new logic has been pushed out with the September CU, it’s conflicting with the old logic and leaving things in a halfway house.
I very much doubt we will see this problem in next month’s patching, as it looks like once September CU is applied, the issue isn’t reproducible when putting hosts in and out of maintenance mode.
Hopefully this helps anyone else coming across this issue